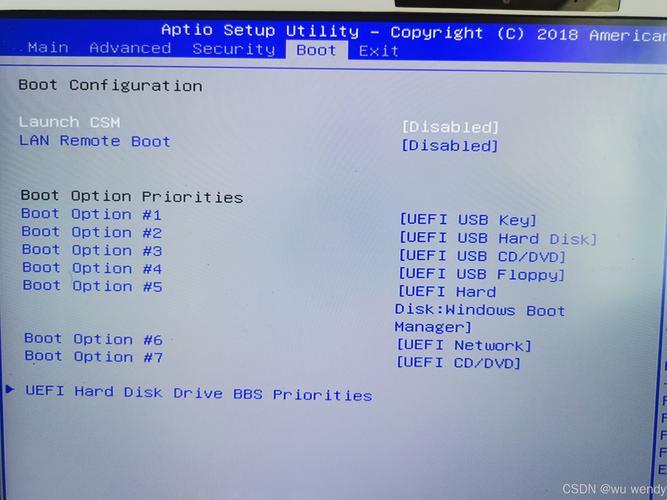
天朗气清,碧空如洗,今日话题:HDFS存储特点,一个让人捧腹、惊叹、抓狂的神奇存在!可谓“一入HDFS深似海,从此悠闲是路人”。(夸张开始了!) 提及HDFS,脑海中顿时浮现“巨大”、“分布式”、“可靠”等字眼,然而,这些看似美好的特点,背后却藏着无数让人啼笑皆非的故事。
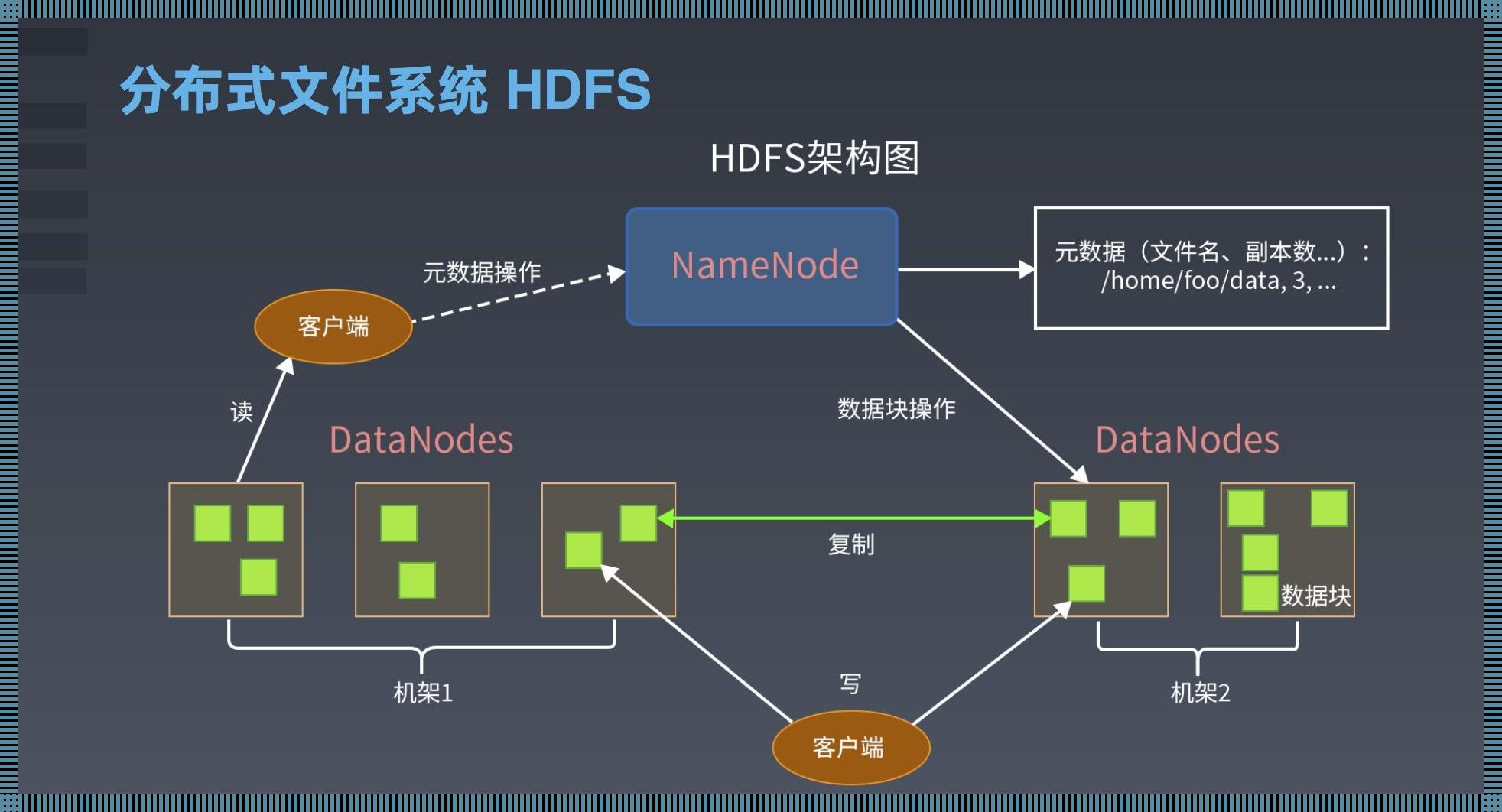
HDFS,全称Hadoop Distributed File System,专为处理超大文件而设计。它能让 TB 级别,甚至 PB 级别的文件存储变得轻松愉快。可是,这么大的文件,你Hold住吗?我反正是一看到就头晕眼花,四肢无力。(自嘲一下)
分布式存储,意味着数据被分散存储在各个节点上。听起来很高大上,实际上却让人抓狂。想象一下,你正在寻找一条数据,它却藏身于成千上万个节点之中,那种感觉,仿佛大海捞针,让人崩溃。
HDFS为了确保数据可靠性,采用了副本机制。数据在不同的节点上存储多个副本,大大提高了数据的可靠性。然而,这背后却隐藏着让人哭笑不得的真相:数据存储成本大大增加,存储空间瞬间被占满。这时候,你只能望盘兴叹,感慨:“数据啊,你为何如此可靠?”
HDFS支持高速写入,这对于大数据处理来说,无疑是一大优势。然而,这背后却让人陷入沉思:数据写入速度越快,存储空间消耗越大,清理数据的频率越高。这不禁让人感叹:“时间就是金钱,数据就是生命,生命不息,清理不止。”
HDFS支持一次写入,多次读取,这听起来似乎很美好。但实际上,这种模式限制了数据的灵活性。当你想要修改数据时,却发现无从下手,这时候,你只能望着HDFS,发出一声叹息:“一次写入,多次读取,我何时才能自由?”
HDFS支持多种编程语言,如Java、Python等,这使得它在数据处理领域备受欢迎。然而,这背后却有一个让人欢喜让人忧的事实:兼容性越好,学习成本越高。当你为了掌握HDFS,熬夜脱发,研究各种编程语言时,是否会感叹:“兼容性,你为何如此迷人?” 总之,HDFS存储特点,让人捧腹,让人惊叹,让人抓狂。在大数据时代,它犹如一匹脱缰的野马,让人难以驯服。然而,正是这些特点,让HDFS在数据处理领域独树一帜,成为无数数据工程师的“心头好”。 最后,我想说:“HDFS,你如此独特,让人如何是好?”(夸张结束,文章完毕)