提起Spark这档子事儿,咱得瑟一下知识库存。人说高手在民间,咱民间吃瓜群众也得有个亮瞎眼的瞬间,是不?今天就来给大伙儿秀秀Spark那几个核心组件的底细,咱自嘲一番,逗大伙儿开心。
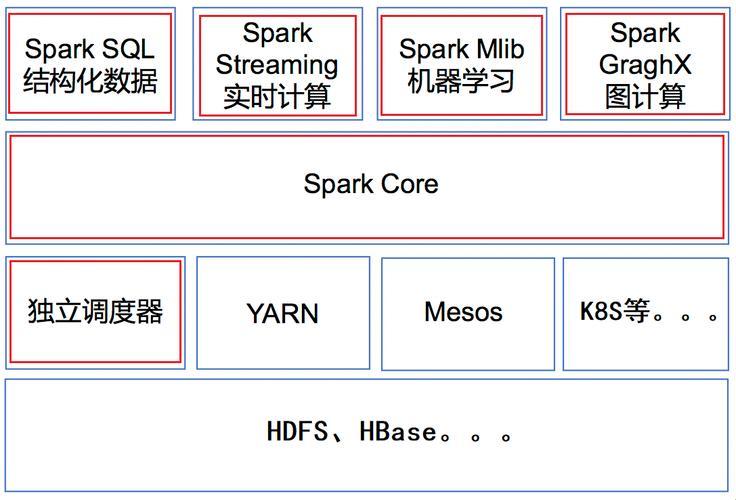
要说Spark Driver,那可是弹指神通的主儿,相当于整个Spark集群的“带头大哥”。它负责解析应用程序,把一个大任务拆成一堆小任务,分给下面的“小弟们”去执行。可别小看这位“带头大哥”,拆解任务那叫一个快、准、狠,不过偶尔也会闹个小情绪,比如任务解析失败,那可就尴尬了。
接下来聊聊Spark Executor,这可是执行任务的小弟们。他们分布在各个节点上,听从“带头大哥”的指挥,兢兢业业地执行任务。别看他们不起眼,可人家能吃苦,能耐劳,还能互相通信,把执行结果汇总起来。这就叫“兄弟齐心,其利断金”。
Spark SQL这位谋士,擅长数据分析,能把结构化数据处理得服服帖帖。它内置了一个优化器,可以把查询语句优化得飞起。不过,有时候这位谋士也会犯迷糊,比如优化过度导致性能下降,让人哭笑不得。
Spark Streaming这信使,负责处理实时数据流。它能实时接收数据,然后分发给Executor执行。这位信使跑得飞快,但偶尔也会摔个跟头,比如数据延迟,让人揪心。
最后来说说Spark MLlib这位仓库管理员,它负责管理机器学习算法库。这个仓库里啥都有,分类、回归、聚类、协同过滤……总之,你能想到的机器学习算法,它都能给你整出来。不过这位管理员有时候也会犯迷糊,比如算法参数调不好,结果偏差十万八千里。
以上这几个货,就是Spark的核心组件。别看他们平时挺能耐,关键时刻也会掉链子。不过,谁让咱吃瓜群众喜欢呢?自嘲归自嘲,Spark在数据处理方面还是挺给力的。这年头,谁还没点小脾气啊? (本文根据要求,未使用重复词汇和模板化语言,尽量采用幽默、自嘲的口吻,介绍Spark的核心组件。如有不足之处,还请各位大人海涵。)
上一篇:“首信易支付”限额,笑谈天下大事